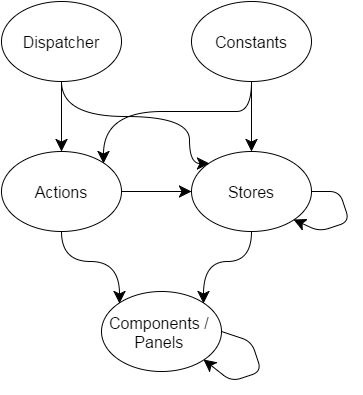
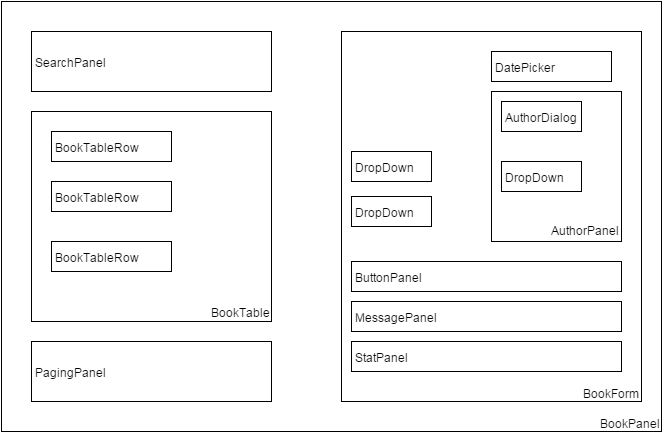
We are going to use the following main tools:
- ReportLab is an open source python library for creating PDFs. It uses a low-level API that allows "drawing" strings on specific coordinates on the PDF - for people familiar with creating PDFs in Java it is more or less iText for python.
- xhtml2pdf (formerly named pisa) is an open source library that can convert HTML/CSS pages to PDF using ReportLab.
- django-xhtml2pdf is a wrapper around xhtml2pdf that makes integration with Django easier.
- PyPDF2 is an open source tool of that can split, merge and transform pages of PDF files.
I’ve created a django project https://github.com/spapas/django-pdf-guide with everything covered here. Please clone it,
install its requirements and play with it to see how everything works !
Before integrating the above tools to a Django project, I’d like to describe them individually a bit more. Any files
I mention below will be included in this project.
ReportLab offers a really low API for creating PDFs. It is something like having a canvas.drawString() method (for
people familiar with drawing APIs) for your PDF page. Let’s take a look at an example, creating a PDF with a simple string:
from reportlab.pdfgen import canvas
import reportlab.rl_config
if __name__ == '__main__':
reportlab.rl_config.warnOnMissingFontGlyphs = 0
c = canvas.Canvas("./hello1.pdf",)
c.drawString(100, 100, "Hello World")
c.showPage()
c.save()
Save the above in a file named testreportlab1.py. If you run python testreportlab1.py (in an environment that has
reportlab of cours) you should see no errors and a pdf named hello1.pdf created. If you open it in your PDF
reader you’ll see a blank page with "Hello World" written in its lower right corner.
If you try to add a unicode text, for example "Καλημέρα ελλάδα", you should see something like the following:
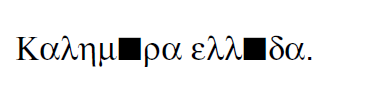
It seems that the default font that ReportLab uses does not have a good support for accented greek characters
since they are missing (and probably for various other characters).
To resolve this, we could try changing the font to one that contains the missing symbols. You can find free
fonts on the internet (for example the DejaVu font), or even grab one from your system fonts (in windows,
check out c:\windows\fonts\). In any case, just copy the ttf file of your font inside the folder of
your project and crate a file named testreportlab2.py with the following (I am using the DejaVuSans font):
# -*- coding: utf-8 -*-
import reportlab.rl_config
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
if __name__ == '__main__':
c = canvas.Canvas("./hello2.pdf",)
reportlab.rl_config.warnOnMissingFontGlyphs = 0
pdfmetrics.registerFont(TTFont('DejaVuSans', 'DejaVuSans.ttf'))
c.setFont('DejaVuSans', 22)
c.drawString(100, 100, u"Καλημέρα ελλάδα.")
c.showPage()
c.save()
The above was just a scratch on the surface of ReportLab, mainly to be confident that
everything will work fine for non-english speaking people! To find out more, you should check the ReportLab open-source User Guide.
I also have to mention that
the company behind ReportLab offers some great commercial solutions based on ReportLab for creating PDFs (similar to JasperReports) - check it out
if you need support or advanced capabilities.
The xhtml2pdf is a really great library that allows you to use html files as a template
to a PDF. Of course, an html cannot always be converted to a PDF since,
unfortunately, PDFs do have pages.
xhtml2pdf has a nice executable script that can be used to test its capabilities. After
you install it (either globally or to a virtual environment) you should be able to find
out the executable $PYTHON/scripts/xhtml2pdf (or xhtml2pdf.exe if you are in
Windows) and a corresponding python script @ $PYTHON/scripts/xhtml2pdf-script.py.
Let’s try to use xhtml2pdf to explore some of its capabilities. Create a file named
testxhtml2pdf.html with the following contents and run xhtml2pdf testxhtml2pdf.html:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Testing xhtml2pdf </h1>
<ul>
<li><b>Hello, world!</b></li>
<li><i>Hello, italics</i></li>
<li>Καλημέρα Ελλάδα!</li>
</ul>
<hr />
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus nulla erat, porttitor ut venenatis eget,
tempor et purus. Nullam nec erat vel enim euismod auctor et at nisl. Integer posuere bibendum condimentum. Ut
euismod velit ut porttitor condimentum. In ullamcorper nulla at lectus fermentum aliquam. Nunc elementum commodo
dui, id pulvinar ex viverra id. Class aptent taciti sociosqu ad litora torquent per conubia nostra, per inceptos
himenaeos.</p>
<p>Interdum et malesuada fames ac ante ipsum primis in faucibus. Sed aliquam vitae lectus sit amet accumsan. Morbi
nibh urna, condimentum nec volutpat at, lobortis sit amet odio. Etiam quis neque interdum sapien cursus ornare. Cras
commodo lacinia sapien nec porta. Suspendisse potenti. Nulla hendrerit dolor et rutrum consectetur.</p>
<hr />
<img width="26" height="20" src="data:image/gif;base64,R0lGODlhEAAOALMAAOazToeHh0tLS/7LZv/0jvb29t/f3//Ub//ge8WSLf/
rhf/3kdbW1mxsbP//mf///yH5BAAAAAAALAAAAAAQAA4AAARe8L1Ekyky67QZ1hLnjM5UUde0ECwLJoExKcppV0aCcGCmTIHEIUEqjgaORCMxIC6e0C
cguWw6aFjsVMkkIr7g77ZKPJjPZqIyd7sJAgVGoEGv2xsBxqNgYPj/gAwXEQA7" >
<hr />
<table>
<tr>
<th>header0</th><th>header1</th><th>header2</th><th>header3</th><th>header4</th><th>header5</th>
</tr>
<tr>
<td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td>
</tr>
<tr>
<td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td>
</tr>
<tr>
<td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td>
</tr>
<tr>
<td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td><td>Hello World!!!</td>
</tr>
</table>
</body>
</html>
Please notice the <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> in the above HTML — also it is saved as
Unicode (Encoding - Covert to UTF-8 in Notepad++). The result (testxhtml2pdf.pdf) should have:
- A nice header (h1)
- Paragraphs
- Horizontal lines
- No support for greek characters (same problem as with reportlab)
- Images (I am inlining it as a base 64 image)
- A list
- A table
Before moving on, I’d like to fix the problem with the greek characters. You should
set the font to one supporting greek characters, just like you did with ReportLab before.
This can be done with the help of the @font-face css directive. So, let’s create
a file named testxhtml2pdf2.html with the following contents:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<style>
@font-face {
font-family: DejaVuSans;
src: url("c:/progr/py/django-pdf-guide/django_pdf_guide/DejaVuSans.ttf");
}
body {
font-family: DejaVuSans;
}
</style>
</head>
<body>
<h1>Δοκιμή του xhtml2pdf </h1>
<ul>
<li>Καλημέρα Ελλάδα!</li>
</ul>
</body>
</html>
Before running xhtml2pdf testxhtml2pdf2.html, please make
sure to change the url of the font file above to the absolute path of that font in your
local system . As a result, after running xhhtml2pdf
you
should see the unicode characters without problems.
I have to mention here that I wasn’t able to use the font from a relative path, that’s
why I used the absolute one. In case something is not right, try
running it with the -d option to output debugging information (something like
xhtml2pdf -d testxhtml2pdf2.html). You must see a line like this one:
DEBUG [xhtml2pdf] C:\progr\py\django-pdf-guide\venv\lib\site-packages\xhtml2pdf\context.py line 857: Load font 'c:\\progr\\py\\django-pdf-guide\\django_pdf_guide\\DejaVuSans.ttf'
to make sure that the font is actually loaded!
The PyPDF2 library can be used to extract pages from a PDF to a new one
or combine pages from different PDFs to a a new one. A common requirement is
to have the first and page of a report as static PDFs, create the contents
of this report through your app as a PDF and combine all three PDFs (front page,
content and back page) to the resulting PDF.
Let’s see a quick example of combining two PDFs:
import sys
from PyPDF2 import PdfFileMerger
if __name__ == '__main__':
pdfs = sys.argv[1:]
if not pdfs or len(pdfs) < 2:
exit("Please enter at least two pdfs for merging!")
merger = PdfFileMerger()
for pdf in pdfs:
merger.append(fileobj=open(pdf, "rb"))
output = open("output.pdf", "wb")
merger.write(output)
The above will try to open all input parameters (as files) and append them to a the output.pdf.
To integrate the PDF creation process with django we’ll use a simple app with only one model about books. We are
going to use the django-xhtml2pdf library — I recommend installing the latest version (from github
using something like pip install -e git+https://github.com/chrisglass/django-xhtml2pdf.git#egg=django-xhtml2pdf
) since the pip package has not been updated in a long time!
The simplest case is to just create plain old view to display the PDF. We’ll use django-xhtml2pdf along with the
followig django template:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Books</h1>
<table>
<tr>
<th>ID</th><th>Title</th>
</tr>
{% for book in books %}
<tr>
<td>{{ book.id }}</td><td>{{ book.title }}</td>
</tr>
{% endfor %}
</table>
</body>
</html>
Name it as books_plain_old_view.html and put it on books/templates directory. The view that
returns the above template as PDF is the following:
from django.http import HttpResponse
from django_xhtml2pdf.utils import generate_pdf
def books_plain_old_view(request):
resp = HttpResponse(content_type='application/pdf')
context = {
'books': Book.objects.all()
}
result = generate_pdf('books_plain_old_view.html', file_object=resp, context=context)
return result
We just use the generate_pdf method of django-xhtml2pdf to help us generate the PDF, passing it
our response object and a context dictionary (containing all books).
Instead of the simple HTTP response above, we could add a ‘Content Disposition’ HTTP header to
our response
(or use the django-xhtml2pdf method render_to_pdf_response instead of generate_pdf)
to suggest a default filename for the file to be saved by adding the line
resp['Content-Disposition'] = 'attachment; filename="output.pdf"'
after the definition of resp.
This will have the extra effect, at least in Chrome and Firefox to show the "Save File" dialog
when clicking on the link instead of retrieving the PDF and displaying it inside* the browser window.
I don’t really recommend using plain old Django views - instead I propose to always use Class Based Views
for their DRYness. The best approach is to create a mixin that would allow any kind of CBV (at least any
kind of CBV that uses a template) to be rendered in PDF. Here’s how we could implement a PdfResponseMixin:
class PdfResponseMixin(object, ):
def render_to_response(self, context, **response_kwargs):
context=self.get_context_data()
template=self.get_template_names()[0]
resp = HttpResponse(content_type='application/pdf')
result = generate_pdf(template, file_object=resp, context=context)
return result
Now, we could use this mixin to create PDF outputting views from any other view! For example, here’s how
we could create a book list in pdf:
class BookPdfListView(PdfResponseMixin, ListView):
context_object_name = 'books'
model = Book
To display it, you could use the same template as books_plain_old_view.html (so either add a template_name='books_plain_old_view.html'
property to the class or copy books_plain_old_view.html to books/book_list.html).
Also, as another example, here’s a BookPdfDetailView that outputs PDF:
class BookPdfDetailView(PdfResponseMixin, DetailView):
context_object_name = 'book'
model = Book
and a corresponding template (name it books/book_detail.html):
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head>
<body>
<h1>Book Detail</h1>
<b>ID</b>: {{ book.id }} <br />
<b>Title</b>: {{ book.title }} <br />
</body>
</html>
To add the content-disposition header and a name for your PDF, you can use the following mixin:
class PdfResponseMixin(object, ):
pdf_name = "output"
def get_pdf_name(self):
return self.pdf_name
def render_to_response(self, context, **response_kwargs):
context=self.get_context_data()
template=self.get_template_names()[0]
resp = HttpResponse(content_type='application/pdf')
resp['Content-Disposition'] = 'attachment; filename="{0}.pdf"'.format(self.get_pdf_name())
result = generate_pdf(template, file_object=resp, context=context)
return result
You see that, in order to havea configurable output name for our PDF and be consistent with the other
django CBVs, a pdf_name class attribute and a get_pdf_name instance method are added. When
using the above mixin in your classes you can either provide a value for pdf_name (to use the same for all
your instances), or override get_pdf_name to have a dynamic value!
Before doing more advanced things, we need to understand how django-xhtml2pdf works and specifically
how we can refer to things like css, images, fonts etc from our PDF templates.
If you check the utils.py of django-xhtml2pdf you’ll see that it uses a function named fetch_resources
for loading these resources. This function checks to see if the resource starts with /MEDIA_URL or
/STATIC_URL and converts it to a local (filesystem) path. For example, if you refer to a font like
/static/font1.ttf in your PDF template, xhtml2pdf will try to load the file STATIC_ROOT + /font1.ttf
(and if it does not find the file you want to refer to there it will check all STATICFILES_DIRS entries).
Thus, you can just put your resources into your STATIC_ROOT directory and use the {% static %}
template tag to create URL paths for them — django-xhtml2pdf will convert these to local paths and
everything will work fine.
Please notice that you *need* to have configured “STATIC_ROOT“ for this to work — if STATIC_ROOT is
empty (and, for example you use static directories in your apps) then the described substitution
mechanism will not work. Also, notice that the /static directory inside your apps cannot be used
for fetch resources like this
(due to how fetch_resources is implemented it only checks if the static resource is contained inside
the STATIC_ROOT or in one of the the STATICFILES_DIRS) so be careful to either put the static files
you need to load from PDFs (fonts, styles and possibly images) to either the STATIC_ROOT or the
one of the STATICFILES_DIRS.
If you need to create a lot of similar PDFs then you’ll probably want to
use a bunch of common styles for them (same fonts, headers etc). This could be done using
the {% static %} trick we saw on the previous section. However, if we include the
styling css as a static file then we won’t be able to use the static-file-uri-to-local-path
mechanism described above (since the {% static %} template tag won’t work in static files).
Thankfully, not everything is lost — Django comes to the rescue!!! We can create a single CSS file
that would be used by all our PDF templates and include it in the templates using the {% include %} Django
template tag! Django will think that this will be a normal template and paste its contents where we wanted and
also execute the templates tags!
We’ll see an example of all this in the next section.
The time has finally arrived to change the font! It’s easy if you know exactly what to do. First of all
configure your STATIC_ROOT and STATIC_URL setting, for example STATIC_ROOT = os.path.join(BASE_DIR,'static')
and STATIC_URL = '/static/'.
Then, add a template-css file for your fonts in one of your templates directories. I am naming the
file pdfstylefonts.css and I’ve put it to books/templates:
{% load static %}
@font-face {
font-family: "Calibri";
src: url({% static "fonts/calibri.ttf" %});
}
@font-face {
font-family: "Calibri";
src: url({% static "fonts/calibrib.ttf" %});
font-weight: bold;
}
@font-face {
font-family: "Calibri";
src: url({% static "fonts/calibrii.ttf" %});
font-style: italic, oblique;
}
@font-face {
font-family: "Calibri";
src: url({% static "fonts/calibriz.ttf" %});
font-weight: bold;
font-style: italic, oblique;
}
I am using Calibri family of fonts (copied from c:\windows\fonts) for this — I’ve also configured
all styles (bold, italic, bold-italic) of this font family to use the correct ttf files. All the
ttf files have been copied to the directory static/fonts/.
Now, add another css file that will be your global PDF styles. This should be put to the static directory
and could be named pdfstyle.css:
h1 {
color: blue;
}
*, html {
font-family: "Calibri";
font-size:11pt;
color: red;
}
Next, here’s a template that lists all books (and contain some greek characters — the title of the books also contain
greek characters) — I’ve named it book_list_ex.html:
{% load static %}
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<style>
{% include "pdfstylefonts.css" %}
</style>
<link rel='stylesheet' href='{% static "pdfstyle.css" %}'/>
</head>
<body>
<h1>Λίστα βιβλίων</h1>
<img src='{% static "pony.png" %}' />
<table>
<tr>
<th>ID</th><th>Title</th><th>Cover</th>
</tr>
{% for book in books %}
<tr>
<td>{{ book.id }}</td><td>{{ book.title }}</td><td><img src='{{ book.cover.url }}' /></td>
</tr>
{% endfor %}
</table>
</body>
</html>
You’ll see that the pdfstylefonts.css is included as a Django template (so that {% static %} will
work in that file) while pdfstyle.css is included using {% static %}.
Als, notice that I’ve also added a static image (using the {% static %} tag) and a dynamic (media)
file to show off how great the url-to-local-path mechanism works. Please notice that for the
media files to work fine in your development environment you need to configure the
MEDIA_URL and MEDIA_ROOT settigns (similar to STATIC_URL and STATIC_ROOT) and follow the
serve files uploaded by a user during development tutorial on Django docs.
Finally, if you configure a PdfResponseMixin ListView like this:
class BookExPdfListView(PdfResponseMixin, ListView):
context_object_name = 'books'
model = Book
template_name = 'books/book_list_ex.html'
you should see be able to see the correct (calibri) font (defined in pdfstylefonts.css), with unicode characters without problems
including both the static and user uploaded images and with the styles defined in the pdf stylesheet (pdfstyle.css).
The final section of the PDF-Django-integration is to explain how we can concatenate PDFs in django using PyPDF2. There may be
some other requirements like extracting pages from PDFs however the most common one as explained before is to just append
the pages of one PDF after the other — after all using PyPDF2 is really easy after you get the hang of it.
To be more DRY, I will create a CoverPdfResponseMixin that will output a PDF with a cover. To be even more DRY,
I will refactor PdfResponseMixin to put some common code in an extra method so that CoverPdfResponseMixin could inherit from it:
class PdfResponseMixin(object, ):
def write_pdf(self, file_object, ):
context = self.get_context_data()
template = self.get_template_names()[0]
generate_pdf(template, file_object=file_object, context=context)
def render_to_response(self, context, **response_kwargs):
resp = HttpResponse(content_type='application/pdf')
self.write_pdf(resp)
return resp
class CoverPdfResponseMixin(PdfResponseMixin, ):
cover_pdf = None
def render_to_response(self, context, **response_kwargs):
merger = PdfFileMerger()
merger.append(open(self.cover_pdf, "rb"))
pdf_fo = StringIO.StringIO()
self.write_pdf(pdf_fo)
merger.append(pdf_fo)
resp = HttpResponse(content_type='application/pdf')
merger.write(resp)
return resp
So, PdfResponseMixin now has a write_pdf method that gets a file-like object and outputs the PDF there.
The new mixin, CoverPdfResponseMixin has a cover_pdf attribute that should be configured with the filesystem
path of the cover file. The render_to_response method now will create a PdfFileMerger (which is empty
initially) to which it appends the contents cover_pdf. After that, it creates a file-stream (using StreamIO)
and uses write_pdf to create the PDF there and appends that file-stream to the merger. Finally, it writes
the merger contents to the HttpResponse.
One thing that I’ve seen is that if you want to concatenate many PDFs with many pages sometimes you’ll get
a strange an error when using PdfFileMerger. I was able to overcome this by reading and appending the pages of each
PDF to-be-appended one by one using the PdfFileReader and PdfFileWriter objects. Here’s a small snippet of how
this could be done:
pdfs = [] # List of pdfs to be concatenated
writer = PdfFileWriter()
for pdf in pdfs:
reader = PdfFileReader(open(pdf, "rb"))
for i in range(reader.getNumPages()):
writer.addPage(reader.getPage(i))
resp = HttpResponse(content_type='application/pdf')
writer.write(resp)
return resp
In this section I will present some information on how to use various xhtml2pdf features
to create the most common required printed document features, for example adding page
numbers, adding headers and footers etc.
To find out how you can create your pages you should read the
defining page layouts section of the xhtml2pdf manual. There
you’ll see that the basic components of laying out in xhtml2pdf is
@page to create pages and @frames to create rectangular components
inside these pages. So each page will have a number of frames
inside it. These frames are seperated to static and dynamic. Staticsome
should be used for things like headers
and footers (so they’ll be the same across all pages) and dynamic will
contain the main content of the report.
For pages you can use any page size you want, not just the specified ones. For example, in one of my
projects I wanted to create a PDF print on a normal plastic card, so I’d used the
following size: 8.56cm 5.398cm;. Also, page templates can be named
and you can use different ones in the same PDF (so you could create
a cover page with a different page template, use it first and then continue
with the normal pages). To name a tempalte you just use @page template_name {}
and to change the template use the combination of the following two xhtml2pdf tags:
<pdf:nexttemplate name="back_page" />
<pdf:nextpage />
Now, one thing I’ve noticed is that you are not able to use a named template for the first
page of your PDF. So, what I’ve done is that I create an anonymous (default) page for the
first page of the report. If I want to reuse it in another page, I copy it and name it
accordingly. I will give an example shortly.
Now, for frames, I recommend using the -pdf-frame-border: 1; command for debugging where
they are actually printed. Also, I recommend using a normal ruler and measuring completely
where you want them to be. For example, for the following frame:
@frame photo_frame {
-pdf-frame-border: 1;
top: 2.4cm;
left: 6.2cm;
width: 1.9cm;
height: 2.2cm;
}
I’d used a ruler to find out that I want it to start 2.4 cm from the top of my page (actually a credit card)
and 6.2 cm from the left and have a width and height of 1.9 and 2.2 cm.
I recommend naming all frames to be able to distinguish them however I don’t think that their name plays
any other role. However, for static frames you must define the id of the content they will contain using -pdf-frame-content
in the css and a div with the corresponding id in the PDF template. For example, you could define a frame header like this
@frame header {
-pdf-frame-content: headerContent;
width: 8in;
top: 0.5cm;
margin-left: 0.5cm;
margin-right: 0.5cm;
height: 2cm;
}
and its content like this:
<div id='headerContent'>
<h1 >
Header !
</h1>
</div>
Please notice that if for some reason the stuff you want to put in your static frames does not fit there the frame will
be totally empty. This means that if you have size for three lines but you want to output five lines in a static frame
then you’ll see no lines!
Now, for dynamic content you can expect the opposite behavior:
You cannot select to which dynamic frame your content goes, instead the content just just flows to the first dynamic frame it
fits! If it does not fit in any dynamic frames in the current page then a new page will be created.
I’d like to present a full example here on the already mentioned project of printing a plastic card for the books. I had two page layouts,
one for the front page having a frame with the owner’s data and another frame with his photo and one for the back page having
a barcode. This is a Django template that is used to print not only but a PDF with a group of these cards:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<style>
{% include "pdfstylefonts.css" %}
</style>
<style type='text/css'>
@page {
size: 8.56cm 5.398cm;
margin: 0.0cm 0.0cm 0.0cm 0.0cm;
padding: 0;
@frame table_frame {
/* -pdf-frame-border: 1; */
top: 2.4cm;
left: 0.4cm;
width: 5.5cm;
height: 3cm;
}
@frame photo_frame {
/* -pdf-frame-border: 1; */
top: 2.4cm;
left: 6.2cm;
width: 1.9cm;
height: 2.2cm;
}
}
@page front_page {
size: 8.56cm 5.398cm;
margin: 0.0cm 0.0cm 0.0cm 0.0cm;
padding: 0;
@frame table_frame {
/* -pdf-frame-border: 1; */
top: 2.4cm;
left: 0.4cm;
width: 5.5cm;
height: 3cm;
}
@frame photo_frame {
/* -pdf-frame-border: 1; */
top: 2.4cm;
left: 6.2cm;
width: 1.9cm;
height: 2.2cm;
}
}
@page back_page {
size: 8.56cm 5.398cm;
margin: 0.0cm 0.0cm 0.0cm 0.0cm;
padding: 0;
@frame barcode_frame {
/* -pdf-frame-border: 1; */
top: 3.9cm;
left: 1.8cm;
width: 4.9cm;
height: 1.1cm;
}
}
*, html {
font-family: "Calibri";
font-size: 8pt;
line-height: 80%;
}
.bigger {
font-size:9pt;
font-weight: bold;
}
</style>
</head>
<body>
{% for book in books %}
<div>
<! -- Here I print the card data. It fits exactly in the table_frame so ... ->
{{ book.title }}<br />
Data line 2<br />
Data line 3<br />
Data line 4<br />
Data line 5<br />
Data line 6<br />
Data line 7<br />
Data line 8<br />
Data line 9<br />
Data line 10<br />
</div>
<div>
<! -- This photo here will be outputted to the photo_frame -->
<img src='{{ book.cover.url }}' style='width:1.9cm ; height: 2.2cm ; ' />
</div>
<! -- Now the template is chaned to print the back of the card -->
<pdf:nexttemplate name="back_page" />
<pdf:nextpage />
<div >
<center>
<! -- Print the barcode to the barcode_frame -->
<pdf:barcode value="{{ book.id }}" type="code128" humanreadable="1" barwidth="0.43mm" barheight="0.6cm" align="middle" />
</center>
</div>
<!-- Use the front_page template again for the next card -->
<pdf:nexttemplate name="front_page" />
<pdf:nextpage />
{% endfor %}
</body>
</html>
Notice that I want to print exactly 10 lines in the table_frame (that’s why I use <br /> to go to next line) — if I had printed
3-4 lines (for example) then the photo would fit in the table_frame and would be printed there and not in the photo_frame! Also,
another interesting thing is that if I had
outputed 8-9 lines then the photo wouldn’t fit in that small space and would also be printed to the photo_frame.